基于Transformer的视频插帧模型
Title:Video Frame Interpolation Transformer
major:CV
Author:Zhihao Shi, Xiangyu Xu, Xiaohong Liu, Jun Chen, Ming-Hsuan Yang
Push:CVPR 2022
code:https://github.com/zhshi0816/Video-Frame-Interpolation-Transformer
简介:
论文提出了一种基于Transformer的视频帧插值框架(VFIT),用于解决视频插值的计算机视觉问题。该框架允许内容感知的聚合权重,并通过自注意操作考虑长距离依赖。为了避免全局自注意的高计算成本,作者引入了局部注意的概念并将其扩展到空间-时间域。此外,提出了一种节省内存的空间-时间分离策略,这也提高了性能。还开发了一种多尺度框架合成方案,以充分实现Transformer的潜力。广泛的实验表明,所提出的模型在多种基准数据集上在定量和定性方面均优于现有最先进的方法。
主要贡献:
- 提出了新颖有效的视频插帧模型
- 提出了时空分离的局部注意力机制
- 提出了多尺度合成方案
研究背景:
最常见的就是由30帧的视频变成60帧。该任务属于依赖性较强的生成问题,通过在现有帧之间合成新帧来时间上对输入视频进行上采样。
这是计算机视觉中的一个基本问题,涉及对运动结构和自然图像分布的理解,有助于诸如图像恢复、虚拟现实和医学成像等众多下游应用
研究限制:
视频信息由于其高纬度,复杂度和计算成本指数上升。当然可以粗暴的把视频作为更高纬度的图片,但是这样失去了很多信息例如时序信息。
CNN曾被用与视频分析,但是卷积操作与内容的时序变化不相关,再者卷积核大小直接影响结果且不能粗暴的通过增加数量来弥补。
大部分视频插帧模型不擅长处理复杂的纹理和运动。
Transformer由NLP改进至视觉领域,再从开销大的全局注意力优化至局部注意力。之前已经有人以此作过图像的研究,作者将其应用在视频上。
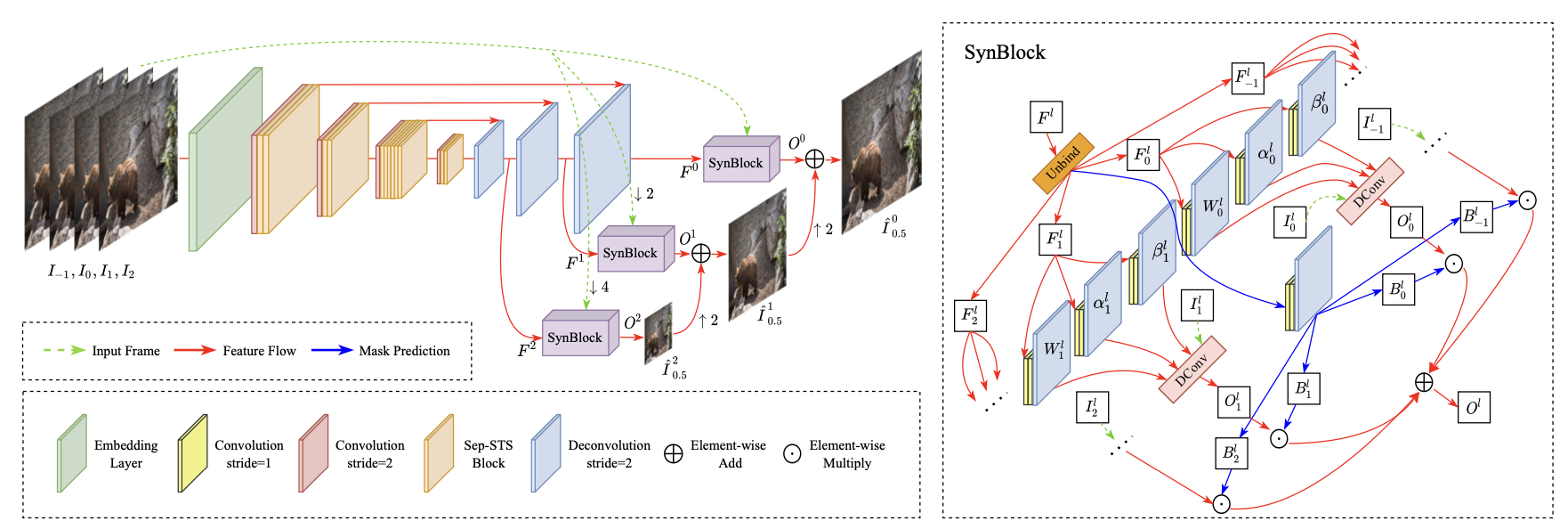
模型架构:
模型分为三部分
1、用3D卷积提取浅层特征
2、使用深层网络获取深层特征
3、使用SynBlocks生成新帧
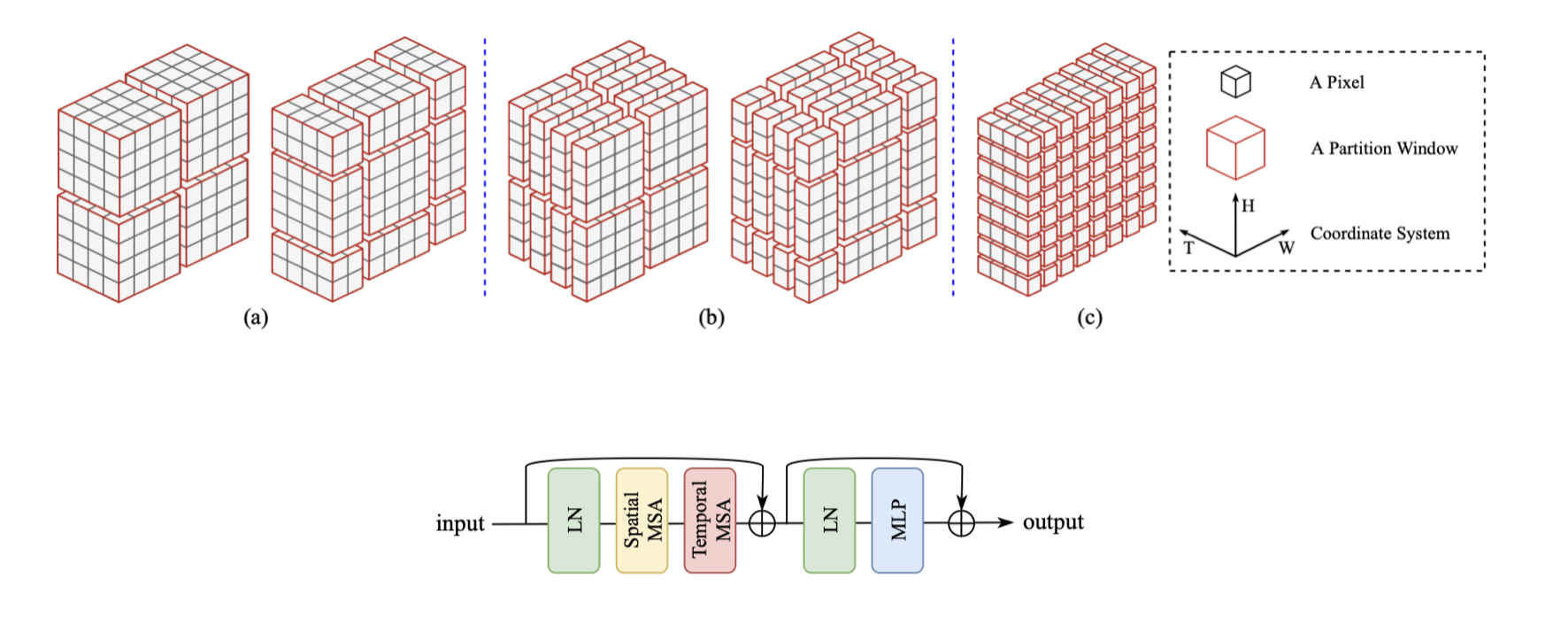
方法论 - 局部注意力机制:
全局注意力开销大,虽然能用分块的方法解决但是影响质量
引入swin的局部注意力机制,但是并不能直接应用于视频
STS:把图3中4纬的图像分割为mm进行第一次多头注意力,之后恢复原状,各边留出m/2后重新分割之后再进行一次多头注意力
Sep-STS:对于空间,将特征图分成2D的块(分离时间),对于时间,将特征图分为TT个向量(分离空间)
引入层正则化优化计算以及GELU激活函数
方法论 - 多尺度合成块:
SynBlocks之后的操作:上一层粗糙图像的上采样(双线性插值)和当前层block输出相加
SynBlocks的输入输出:1、对于l层特征,按帧抽出后放进三个卷积层2、卷积层输出的结果与原帧融合3、输出结果与特征直接卷积的值相乘4、最后将所有帧相加
实验细节:
模型训练:loss 绝对值损失、opt adamax、evaluate PSNR&SSIM、dataset Vimeo-90K 等
训练环境:desktop with an Intel Core i7-8700K CPU and an NVIDIA GTX 2080 Ti GPU
模型设计了基础版VFIT- B和简单版VFIT- S,与现有的模型做了对比实验。除此之外还做了消融实验。
结论:
本文提出了一种参数节省、运行高效的VFIT框架,用于视频帧插值,性能达到了最先进水平。
使用了时间空间分离的局部注意力机制,本想考虑时空特征的前提下节省计算成本,但是得到了更好的效果。
使用了多尺寸生成块,同时考虑多个维度的特征,结合原帧的基础上从粗糙到细致优化生成帧。
展望:
本文的损失函数是最简单的绝对值损失,并且只作用于结果部分。作者尝试分块计算损失值但并不是很理想。
本文使用的上下采样方式是双线性插值法,本以为用Transformer架构会更好但得到了较差的结果,这点具有研究价值。
本文不仅适用于简单的视频,还可以拓展到其他具有时序逻辑的应用上。并且本文是泛用的视频生成帧,可以试着专攻某一个固定的事物进行生成。